2.1.3. Standards et interopérabilité
¶ 1 Commenter le paragraphe 1 0 Note pour les relecteurs : comme la précédente, cette partie n’est pas encore tout à fait achevée, mais au vu de mon retard, il est urgent que j’avance.
¶ 2 Commenter le paragraphe 2 4 Si l’intérêt pour l’annotation est aujourd’hui largement répandu, l’absence de standards et de normes représente un véritable frein à la généralisation et à la valorisation de l’annotation sur internet. Ainsi, rien n’assure actuellement largement l’interopérabilité et la pérennité des annotations produites. Reconnaissant la valeur montante de l’annotation sur le web ; conscient de ses potentialités, mais aussi de ses limites, le W3C tente actuellement d’y suppléer en proposant une norme, Open Annotation Standard.
2.1.3.1. Les limites de l’annotation : la nécessité de standards
¶ 3 Commenter le paragraphe 3 2 Les limites et obstacles à l’extension des pratiques d’annotation sur le web sont en grande partie imputables à l’absence de standards et de solutions techniques satisfaisantes. Cependant, la première entrave est entièrement imputable aux fournisseurs de services qui enferment les annotations produites par l’utilisateur dans leur plateforme ou logiciel, n’offrant aucune solution technique pour les exporter, les partager, les syndiquer ou les réutiliser. C’est notamment le cas des deux principaux écosystèmes de lectures, Kobo et Amazon, qui interdisent aux lecteurs d’extraire les annotations pour les réutiliser dans d’autres applications. Par exemple, les annotations produites dans l’application Kindle d’Amazon ne peuvent pas être transférées sur l’application iBook d’Apple, quand bien même le lecteur posséderait le même livre dans les deux écosystèmes ! De fait, bien que produites par le lecteur, ces annotations deviennent propriété de l’éditeur de la plateforme.
¶ 4 Commenter le paragraphe 4 4 Ces difficultés ne sont pas seulement le fait d’une mauvaise volonté de la part des diffuseurs de ressources et concepteurs des plateformes, mais également tributaire de la technologie. En effet, plusieurs difficultés techniques font obstacle aux pratiques d’annotations.
¶ 5 Commenter le paragraphe 5 2 Tout d’abord, il n’existe aucun format ouvert et standard pour les annotations, c’est-à-dire un mode de représentation des données dont les spécifications sont connues, standardisées et sans restriction d’accès, ce qui en assure l’interopérabilité. Selon les outils, les annotations sont produites dans des formats propriétaires (fermés) ou dans divers formats ouverts, sans qu’il soit entendu d’un format standard à employer.
¶ 6 Commenter le paragraphe 6 11 Ensuite, il n’existe aucune règle concernant le pointage vers la ressource annotée. Une annotation étant apposée sur un contenu et ne pouvant se comprendre indépendamment de celui-ci, il est indispensable que ce lien entre les deux ressources demeure pérenne. Or, les ressources annotées peuvent être de différents formats (image, texte, PDF, HTML, flux vidéo…) et sont susceptibles de disparaître (lien brisé, suppression de la ressource sur le serveur…) : il est donc très difficile de lier l’annotation au contenu annoté. Les outils proposent à cette problématique technique des solutions diverses, dont aucune n’est véritablement satisfaisante. Concernant l’annotation du HTML, il est fréquent que le pointage repose sur XPointer (une spécification du W3C permettant de désigner un fragment de document XML désigné par une URI grâce à la syntaxe XPath qui forme un chemin de localisation) ou simple comptage des caractères dans un flux textuel. Ces solutions n’assurent cependant pas un pointage efficace en cas de changement de l’URL ou de modification importante dans la ressource annotée. De fait, les problématiques de versioning des ressources, pourtant centrales (internet est un média facilement actualisable, ce qui fait sa force) sont très mal gérées par les outils d’annotations.
¶ 7 Commenter le paragraphe 7 3 Enfin, aucun standard n’est établi quant aux métadonnées qui doivent être attachées aux annotations : lesquelles doivent être indispensables ? Comment les formuler ? Ainsi, est-il nécessaire que toutes les annotations soient reliées à leur auteur ? Si oui, selon quel protocole ? Comment gérer les droits d’affichage et de modification ? Par quel biais indexer le contenu des annotations elles-mêmes ? En effet, les annotations forment des ressources, et il peut être bénéfique de les référencer au même titre que les contenus qu’elles commentent, mais encore faut-il disposer de standards.
¶ 8 Commenter le paragraphe 8 0 L’établissement de standards propres à l’annotation assurerait d’une part l’interopérabilité des ressources produites et d’autre part leur pérennité. C’est d’autant plus important de notre point de vue du fait que, pour que l’annotation s’intègre aux pratiques de la recherche, il est nécessaire d’assurer : la pérennité des contenus, la stabilité des liens de pointage, l’interopérabilité des annotations, des moyens de contrôle des accès et la qualité des métadonnées. Ainsi seulement les annotations formeront un matériau stable et citable pour la recherche.
¶ 9 Commenter le paragraphe 9 2 Il est nécessaire ici de souligner que les problématiques des chercheurs face à l’annotation sont les mêmes que celles des architectes du web : nous observons une convergence étonnante entre les bonnes pratiques traditionnelles de la recherche et celles du numérique.
2.1.3.2. Les acteurs
¶ 10 Commenter le paragraphe 10 4 Face au défi d’un standard de l’annotation, plusieurs grands organismes se sont positionnés, parmi lesquels de W3C. À travers différents groupes et conférences se dessine un futur standard pour l’annotation.
¶ 11 Commenter le paragraphe 11 2 Fondé par Tim Berners-Lee en 1994, le World Wide Web Consortium (W3C) est un organisme à but non lucratif dont la mission première est d’établir et de maintenir des normes et de promouvoir la comptabilité des technologies qui forment le World Wide Web afin d’assurer « un seul web partout et pour tous[1] ». Dès le début des années 2000, le W3C avait déjà formulé un standard d’annotation du web, appelé Annotea. Il reposait sur des triplets RDF favorisant la production de métadonnées. Ce standard avait été mis en œuvre dans le navigateur Amaya. Le projet Annotea a été abandonné au milieu des années 2000 car il ne correspondait plus aux derniers développements du web : en effet, il avait été conçu pour l’annotation des pages web et non des ressources multimédias (vidéo, images). Par ailleurs, il n’incluait pas la dimension temporelle, reconnue aujourd’hui comme essentielle. Enfin, Annotea avait été enrichi de nombreuses extensions, nuisant à la cohérence d’ensemble.
¶ 12 Commenter le paragraphe 12 5 La volonté de créer un modèle standard pour l’annotation est réactivée à la fin des années 2000. En 2009, la fondation Andrew W. Mellon accorde un financement d’un montant de 362 000 $ à l’Open Annotation Collaboration, qui travaille tant sur l’établissement d’une norme que sur le développement d’outils. Dans le but de produire une norme, deux groupes sont crées au sein du W3C : Open Annotation Model et Annotation Ontology, l’un chargé d’établir un modèle de données et l’autre de réfléchir à un vocabulaire commun.Fin 2011, ces deux groupes se sont rassemblés au sein de Open annotation Community group où ils collaborent à un projet commun de spécification pour l’annotation, basé sur RDF, en tenant compte des exigences et cas d’utilisation identifiés par leurs travaux antérieurs. Comptant 127 membres (universitaires, employés de sociétés commerciales, membres d’organisations à but non lucratif), le groupe communautaire est dirigé par Paolo Ciccarese et Robet Anderson. Au cours de l’année 2013, Open annotation Community group a pu divulguer son produit final, un cahier des charges. De ce fait Open annotation Data Model, publié le 8 février 2013 est un « community draft », c’est-à-dire une spécification émanent du groupe et non standard du W3C. Il doit ainsi être considéré comme un document de travail et non comme un référent. En août 2014, un groupe de travail (Web annotation Working Group, présidé par Rob Sanderson et Fredrick Hirsch) a été crée au W3C : il a pour but de publier un standard pour l’annotation, sur la base de ce brouillon fourni par Open annotation Community group. La publication de ce standard est prévue pour le 1er octobre 2016. Parallèlement, des projets sont déjà en cours pour inclure Open Annotation dans le développement de l’Epub3.
¶ 13 Commenter le paragraphe 13 1 Par ailleurs, différentes rencontres professionnelles sont l’occasion de collaborer et d’avancer sur la question d’un standard d’annotation ouvert. Parmi elles, I Annotate est la plus spécialisée. La première édition de cette conférence a eu lieu à San Francisco en 2013, suivi d’une seconde rencontre en 2014. Rassemblant une centaine de spécialistes de l’annotation, I Annotate est organisée à l’initiative de Rob Anderson et d’Hypothes.is avec le soutien financier de la fondation Andrew W. Mellon.
¶ 14 Commenter le paragraphe 14 2 La force d’I Annotate est de rassembler un large éventail d’acteurs de l’annotation numérique : des industriels, des universitaires, des bibliothécaires, des start-ups, des doctorants et chercheurs, des porteurs de projets en Digital Humanities. I Annotate est l’occasion de présenter des projets (logiciels et leurs applications), disserter sur l’histoire et l’avenir de l’annotation, expérimenter de nouvelles solutions lors de workshops, innover pendant un hackathon ou encore échanger sur les normes en construction. Ainsi, les sessions couvrent des questions aussi larges que : les plateformes d’annotation, l’implémentation et l’utilisation des outils d’annotations, les communautés et la mise en œuvre d’annotations.
¶ 15 Commenter le paragraphe 15 1 D’autres rencontres, moins spécialisées, sont également l’occasion d’échanger sur l’annotation. Ainsi, Books in Browser, Tools of Change et les Digital Humanities Days comptent de nombreuses conférences et débats sur les futurs standards et pratiques de l’annotation. Les comptes-rendus, captations vidéo et résumés de tous ces événements forment une part essentielle de la bibliographie de ce mémoire.
2.1.3.3. Focus sur Open Annotation
¶ 16 Commenter le paragraphe 16 5 Projet du W3C porté successivement par Open annotation Model, Annotation Ontology et Open Annotation Community group, la spécification Open annotation est en cours d’établissement par Web annotation Working group dont le travail sera publié en octobre 2016. Il s’agit de spécifier un cadre interopérable pour la création d’annotations, c’est-à-dire un modèle de données génériques pour les annotations, et de définir les éléments d’infrastructure de base pour le rendre déplorable à la fois dans les navigateurs et les applications de lecture par le biais d’interfaces utilisateurs appropriées. L’ambition est de rendre partageables les annotations d’un client à un autre (au-delà des plateformes) et d’adopter le linked Data dans les annotations. Plus largement, c’est repenser les annotations sur le web tout en accordant la priorité aux annotations savantes. La spécification retenue doit offrir une richesse d’expression suffisante pour satisfaire aux exigences les plus complexes tout en restant assez simple pour permettre les utilisations les plus courantes.
¶ 17 Commenter le paragraphe 17 3 Pour fournir une synthèse du futur standard Open Annotation, je me suis appuyée sur le « community draft » Open annotation Data Model publié le 8 février 2013 et la chartre du Web annotation Working Group, publiée le 22 août 2014.
¶ 18 Commenter le paragraphe 18 1 Le groupe de travail Web annotation Working Group travaille sur six points majeurs :
- Un modèle abstrait de données pour les annotations.
- Un vocabulaire décrivant et définissant le modèle des données.
- Un ou plusieurs formats de sérialisation du modèle abstrait de données.
- Une spécification d’API HTTP pour créer, éditer, accéder, chercher, gérer et manipuler des annotations via le protocole HTTP.
- Une API-client (interface et évènements de script) pour faciliter la création de systèmes d’annotation dans un navigateur ou via un plug-in.
- Un système de lien d’ancrages robustes soit des mécanismes permettant de cibler de façon pérenne et interopérable les fragments de ressources, en supportant au maximum les modifications éventuelles de celles-ci.
¶ 20 Commenter le paragraphe 20 3 Concernant le modèle abstrait de données et le vocabulaire, le travail de l’Open Annotation Community group fournit une base de réflexion très élaborée. En termes généraux, une annotation exprime la relation entre deux ou plusieurs ressources, et leurs métadonnées, en utilisant un graphe RDF (Ressource Description Framework) . Dans son modèle de base (Baseline Model) : une annotation est un document identifié par une URI HTTP et qui décrit l’association créée entre deux ressources (body et target). <Body> forme le corps de l’annotation, c’est-à-dire le commentaire ou une autre ressource descriptive tandis que <target> cible la ressource à propos de laquelle il est question. Le modèle impose donc que l’annotation soit associée à la classe oa : annotation et définit deux relations : oa : hasBody et oa : hasTarget.
¶ 21
Commenter le paragraphe 21 0
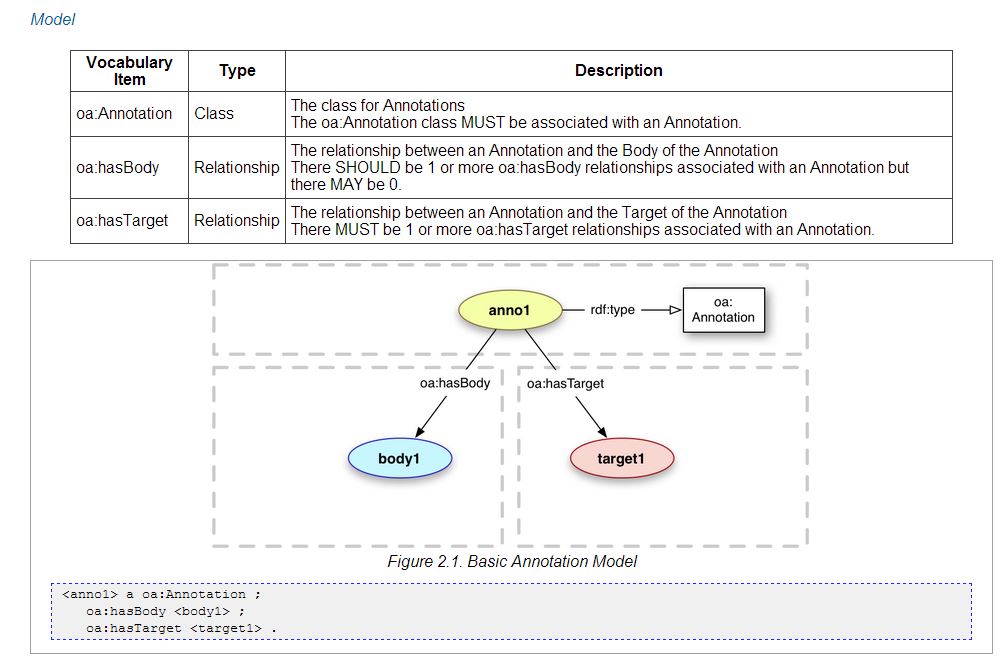
¶ 22 Commenter le paragraphe 22 1 Il s’agit du modèle de base, qui peut être augmenté de nombreuses fonctionnalités supplémentaires. Ainsi, il est possible typer les ressources entrant en jeu dans <Body> et <Target> (Texte, image, audio, vidéo) à l’aide de Dublin Core Types vocabulary. Le modèle gère également l’ajout de tags et de tags sémantiques à l’aide des classes oa : tag et oa : SemanticTag, mais aussi la caractérisation de la nature des annotations grâce à la classe oa : motivation.
¶ 23 Commenter le paragraphe 23 2 Le modèle abstrait de données permet enfin la gestion d’annotation complexe impliquant des ressources multiples (plusieurs body ou target).
¶ 24 Commenter le paragraphe 24 1 Enfin, il envisage des manières d’enregistrer les informations quant au créateur de l’annotation.
¶ 25 Commenter le paragraphe 25 1 Concernant la sérialisation, le W3C envisage un format en HTML (avec du RDFa), car les annotations existantes sont souvent stockées ainsi et un format plus adapté à l’intégration des métadonnées dans le média (Json ou Json-LD).
¶ 26 Commenter le paragraphe 26 1 La question des liens d’ancrages robustes est certainement la plus complexe. En effet, il s’agit de cibler des fragments de ressources de toutes natures (textes, images, vidéo, son) de façon la plus précise et pérenne possible. En effet, les ressources ciblées sont susceptibles d’évoluer. Le mécanisme reposera sur une URL et plusieurs sélecteurs. Pour ce travail, le Web annotation Working Group s’appuiera sur les mécanismes définis par dans les spécifications publiées par le W3C le 25 septembre 2012 « Media Fragments URI 1.0 »
¶ 27 Commenter le paragraphe 27 0
¶ 27 Commenter le paragraphe 27 0 [1] http://www.w3c.fr/a-propos-du-w3c-france/la-mission-du-w3c/
Hello! efkeegk interesting efkeegk site! I’m really like it! Very, very efkeegk good!
Hello! bckfefa interesting bckfefa site! I’m really like it! Very, very bckfefa good!
Hello!
Hello!
Sorry but,
Very nice,
Perfect!
Hello!
Hello!
Sorry but,
Welcome!
Commentaire attendant validation